AI Agents: Applications & Builds
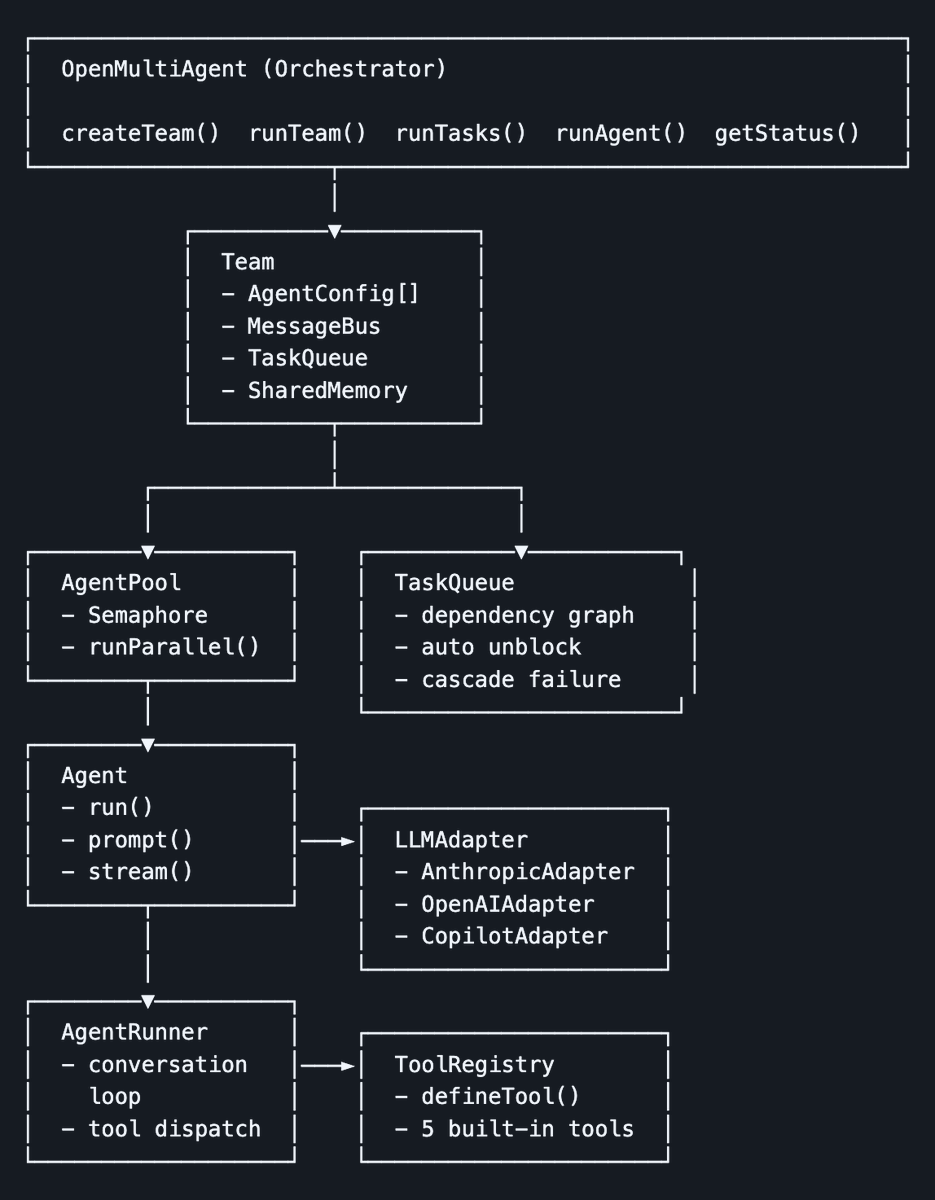
Goal To save humans wasting time sitting in Call Centre queues waiting to be answered To have tool listen in on the audio stream of a live call, post IVR Navigation - to determine whether the call has transitioned out. (2410.08235) LLM-based multi-agent systems have demonstrated strong performance across complex real-world tasks, such as software engineering, predictive modeling, and retrieval-augmented generation. (arXiv:2605.13295) Recent development of agents has renewed demand for long-context reasoning capacity of LLMs. However, training LLMs for this capacity requires costly...
This matters because practical agent use cases are widening, but the durable signal is whether they solve repeated workflows instead of one-off demos. The multi-source signal is worth tracking for changes in capability, deployment friction, or operating risk.
Image/Video GenAI: Tools & Workflows

Was working on a personal project where I needed masks for a large custom image dataset. Tried the official SAM notebooks, but they felt more like demos than something practical for segmentation mask generation workflows, so I built a small tool around it over the weekend. (sam interactive.ipynb) Aligning Text-to-Image (T2I) generation models with human preferences increasingly relies on image reward models that score or rank generated images according to prompt alignment and perceptual quality. (AutoRubric-T2I: Robust Rule-Based Reward Model for Text-to-Image Alignment) I'm not the author of...
This matters because visual generation is shifting from novelty outputs toward controllable production workflows. The multi-source signal suggests builders should watch tools that improve editing precision, repeatability, and model integration.
3D Gaussian Splatting: Tools & Reconstruction

Robust training and validation of Autonomous Driving Systems (ADS) require massive, diverse datasets. (Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving) Multimodal Large Language Models (MLLMs) have made rapid progress in spatial intelligence, yet existing spatial reasoning benchmarks largely assume pristine visual inputs and overlook the degradations that commonly. (SpaceDG: Benchmarking Spatial Intelligence under Visual Degradation) Many public buildings provide floorplans with a "you are here" indicator to help visitors orient themselves. Floorplan localization...
This matters because Gaussian splatting progress is increasingly judged by usable pipelines, not just reconstruction quality. The multi-source signal points to continued movement from research artifacts toward viewers, mesh conversion, and production workflows.
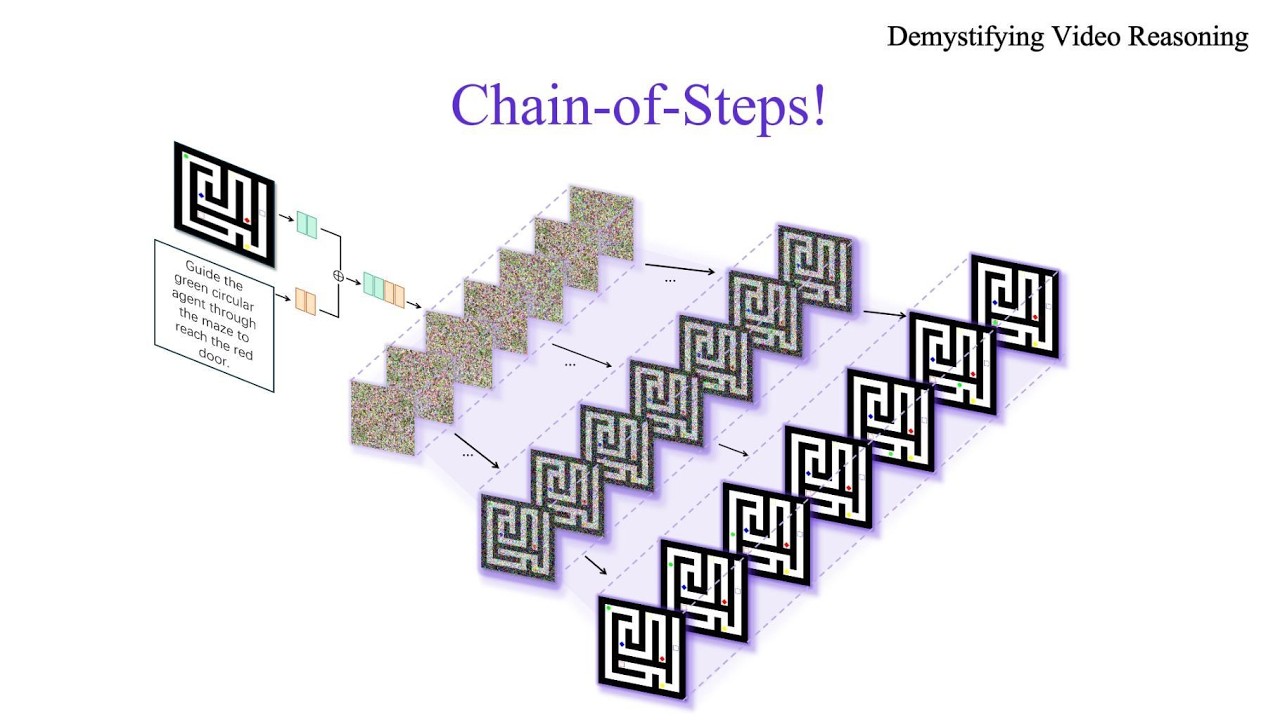
Generative 3D Worlds: Explorable World Models
World models learn compact latent representations for planning without pixel reconstruction. LeWorldModel (LeWM), from LeCun's group at NYU, achieves stable end-to-end JEPA training by enforcing an isotropic Gaussian prior over the full latent space. (2605.09241) Simulation-ready physical 3D assets have emerged as a promising direction owing to their broad applicability in downstream tasks. (PhysX-Omni: Unified Simulation-Ready Physical 3D Generation for Rigid, Deformable, and Articulated Objects) Autoregressive video diffusion models have enabled real-time, action-conditioned world...
This matters because world-generation systems are moving from rendered clips toward persistent spaces that can be explored, edited, and exported into production tools. The multi-source signal is worth tracking for signs that 3D asset creation and simulation workflows are becoming model-driven.
Also Notable
[R] FIKA-Bench: From Fine-grained Recognition to Fine-Grained Knowledge Acquisition
We are releasing FIKA-Bench: From Fine-grained Recognition to Fine-Grained Knowledge Acquisition , a benchmark for evaluating whether multimodal agents like OpenClaw can actively acquire fine-grained knowledge from external evidence. The motivation is that many fine-grained visual recognition benchmarks are still close to a closed-set classification setting: given an image, the model is expected to output a label...
Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles
The proliferation of large language models (LLMs) and modular skills has endowed autonomous agents with increasingly powerful capabilities. Existing frameworks typically rely on monolithic LLMs and fixed logic to interface with these skills. This gives rise to a critical bottleneck: different LLMs offer distinct advantages across diverse domains, yet current frameworks fail to exploit the complementary strengths of...
TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
Public transit route planning traditionally depends on structured map infrastructure and complex routing engines, and no existing dataset supports training models to bypass this dependency. We present TransitLM, a large-scale dataset of over 13 million transit route planning records from four Chinese cities covering 120,845 stations and 13,666 lines, released as a continual pre-training corpus and benchmark data for...
Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Spreadsheet systems (e.g., Microsoft Excel, Google Sheets) play a central role in modern data-centric workflows. As AI agents grow increasingly capable of automating complex tasks, such as controlling computers and generating presentations, building an AI-driven spreadsheet agent has emerged as a promising research direction. Most existing spreadsheet agents rely on specialized prompting over general-purpose LLMs...
ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning
Large language models (LLMs) and agentic systems have shown promise for clinical decision support, but existing works largely assume that evidence has already been curated and handed to the model. Real-world clinical workflows instead require agents to actively seek, iteratively plan, and synthesize multimodal evidence from heterogeneous sources. In this paper, we introduce ClinSeekAgent, an automated agentic...
π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
The rise of personal assistant agents, e.g., OpenClaw, highlights the growing potential of large language models to support users across everyday life and work. A core challenge in these settings is proactive assistance, since users often begin with underspecified requests and leave important needs, constraints, or preferences unstated. However, existing benchmarks rarely evaluate whether agents can identify and act...